
テキストから音楽を自動生成する「Riffusion」が凄い。新たなAI作曲プロジェクト
文章から画像を自動生成する、オープンソースのAIモデル「Stable Diffusion」 が話題になりましたが、今回はSeth ForsgrenとHayk Martirosという2人の開発者が同じモデルを使用して、テキストを音楽に変換する「Riffusion」を作成しました。
趣味のプロジェクトとして開発されたRiffusionは、スペクトグラムから画像を生成し、それをオーディオクリップに変換することで音楽を自動生成します。「シード」を変えることでプロンプトの無限のバリエーションを生みだすことができます。
スペクトグラムとは、音声信号を周波数成分に分解したグラフのことです。グラフは時間軸と周波数軸で表され、スペクトグラムを作成するためには、信号をSTFT(フーリエ変換)する必要があります。フーリエ変換は、信号を周波数成分に分解する手法であり、信号を周波数領域で表すことができます。
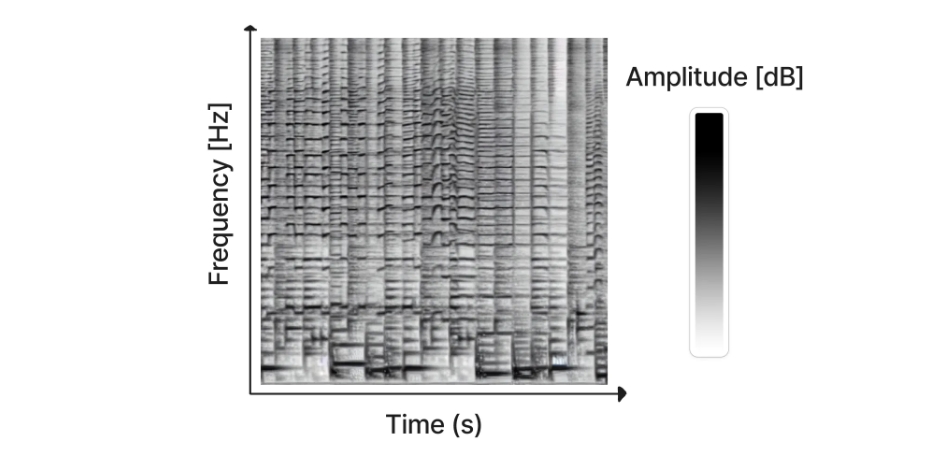
スペクトグラムは、信号の特徴をわかりやすく表すために使われます。例えば、スペクトグラムを見ることで、発音された単語を特定したり、楽器や演奏されている曲を特定することも可能になります。
ただし、Riffusionの場合には、オーディオをスペクトログラムから再構築できるように、STFTが反転されます。学習の難しいとされる位相は含まれておらず、画像モデルのスペクトログラムイメージには正弦波の振幅のみが含まれています。位相の近似要素として、Griffin Rimアルゴリズムが使われています。
実際に使ってみた
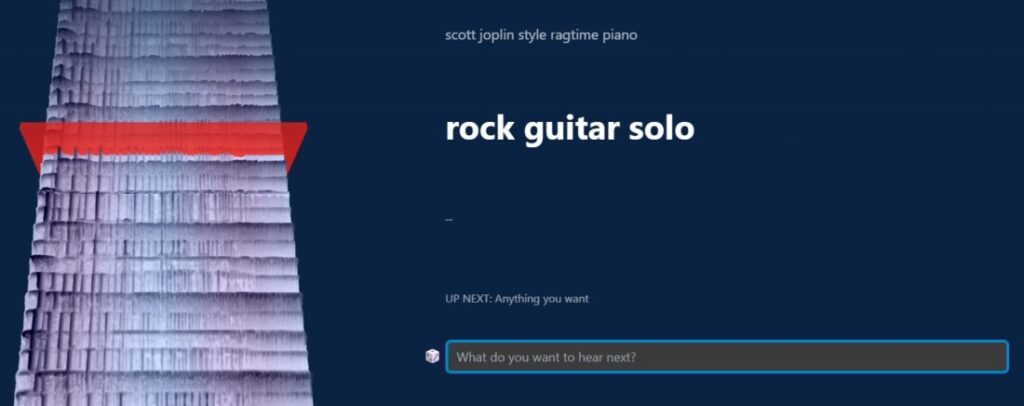
Web上で実際に使用してみると、テキストプロンプトを入力することで、スペクトログラムの視覚的な3Dが流れながら、音楽をリアルタイムで生成し続けることができます。
「Piano Concert in A Minor」「Bossa nova with Distorted Guitar」や「K-Pop Girls Group」といった楽器の種類や音楽ジャンル、雰囲気などを入力することで、音楽を自動生成してくれます。
異なるプロンプトを入力しても、プロンプトとシードの間をスムーズに補間して滑らかに音楽を繋いでくれるので、無限のループ音楽を生成することが可能になっています。
現在のところRiffusionは、音楽を自動作曲する為の壮大なプロジェクトではなく、「面白いものできたから使ってみて!」という開発者による趣味的なプロジェクトとされているようです。
「ここから進むべき方向はたくさんあり、その過程で学び続けることに興奮しています。今朝、私たちのコードの上に他の人がすでに独自のアイデアを構築しているのを見るのも楽しかったです。Stable Diffusionコミュニティの驚くべき点の 1 つは、元の作成者が予測できない方向性で、新しいものが構築されていく速さです。」




