
Metaが誰でも利用できるオーディオ生成AI「AudioCraft」を発表
Metaが、テキストプロンプトから音楽や音声を生成するための生成AIツールである「AudioCraft」をオープンソース化すると発表しました。
これらのツールを使用することで、コンテンツクリエイターは簡単なテキストの説明を入力するだけで、環境音声を生成したり、メロディーを作曲したり、あるいはバーチャルオーケストラをシミュレートしたりすることができるようになります。
3つのテクノロジーを搭載
AudioCraftには3つの生成モデルで構成されています。1つ目は「AudioGen」で、さまざまな音響効果や音景を生成するツールです。2つ目は「MusicGen」で、説明から音楽作品やメロディを生成することができます。そして3つ目は「EnCodec」で、ニューラルネットワークを基にした音声圧縮コーデックです。
EnCodecが最近改良され、「より少ないアーティファクトで高品質な音楽生成が可能になる」と述べています。また、AudioGenは犬の吠え声や車のクラクション、木の床を歩く足音などの音声効果を生成できます。MusicGenでは、例えば「キャッチーなメロディー、トロピカルなパーカッション、アップビートなリズムが特徴のビーチにぴったりのダンストラック」といったテキストに基づいて、さまざまな楽曲をゼロから作成することができます。
音楽生成AIの波がくる

Metaは、テキストや静止画を中心とした生成AIモデルは多くの注目を集めており、実際に仕事に取り入れることができる水準に達していますが、音声生成ツールの開発は遅れていると指摘しています。
音楽生成AIのウェブサイトでいくつかのオーディオサンプルを聴くことができますが、テキストプロンプト通りの音楽は生成できていますが、プロフェッショナルによって制作された楽曲や、音声効果に置き換えるにはまだ早いと言える品質です。
「いくつかのAI研究は存在しますが、非常に複雑でオープンではないため、一般の人達が簡単に試すことができません」と述べています。しかし、彼らはAudioCraftがMITライセンスの下で公開され、オーディオや音楽の実験のためのアクセス可能なツールを提供することで、広くコミュニティに貢献することを期待していると述べています。
オープンソースでの公開

「これらのモデルは研究目的および技術の理解をさらに深めるために利用できます。研究者や実践者が初めて自分のデータセットで独自のモデルを訓練し、技術の最先端を推進するのにアクセスできることを楽しみにしています」とMetaは述べています。
AIによる音声と音楽生成の実験は今回が初めてのことではありません。注目すべき最近の試みとして、OpenAIは2020年に「Jukebox」を発表し、Googleは2021年1月に「MusicLM」を発表し、そして昨年12月には独立した研究チームがStable Diffusionベースでテキストから音楽を生成するプラットフォーム「Riffusion」を作成しました。
これらの生成音声プロジェクトは、画像合成モデルほど多くの注目を集めているわけではありませんが、それは開発プロセスが複雑さに欠けるわけではないと、ウェブサイトで指摘しています。
感動を与えるのは難しい

色んなジャンルの高品質オーディオを生成するには、さまざまなスケールで複雑な信号とパターンをモデル化する必要があります。音楽はおそらく最も難しいタイプの音声生成であり、ノートの組み合わせから複数の楽器を持つグローバルな楽曲構造まで、様々なパターンで構成されています。
AIによる連続した音楽の生成は、しばしばMIDIやピアノロールなどの象徴的な表現を使用して取り組まれてきましたが、これらのアプローチは音楽に見られる細かい表現や、繊細なニュアンス、スタイル要素を完全に把握することができません。
より最近の進歩では、音楽を作るために、自己教示型の音声の特徴を学ぶ方法や、階層的なモデルを使った手法が使われています。これらの手法では、生の音を複雑な仕組みに入れて、音楽の長い範囲の構造を捉えながら、高品質な音楽を生成しています。
オーディオ生成へのシンプルなアプローチ
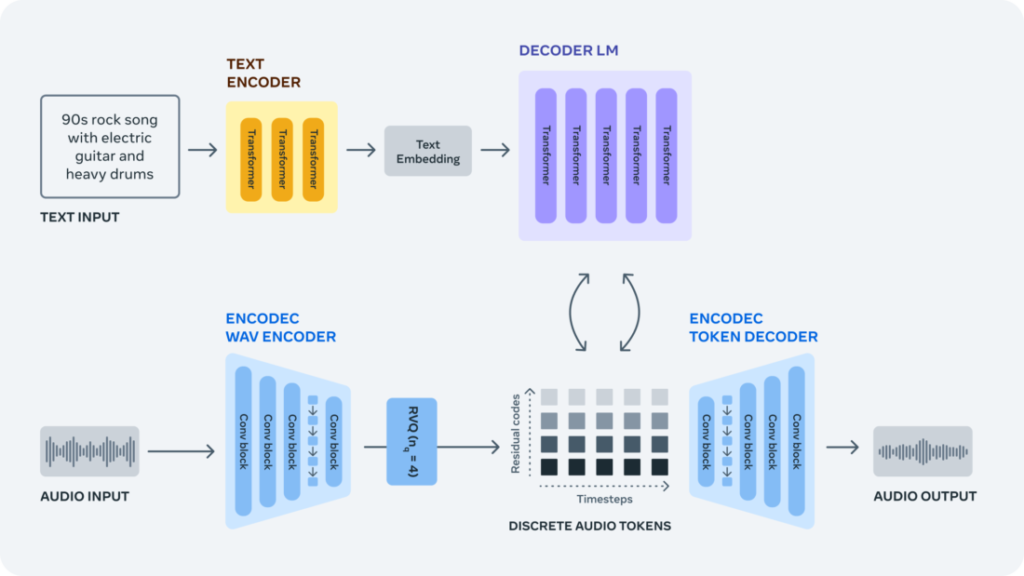
生のオーディオ信号からオーディオを生成することは、非常に長いシーケンスをモデリングする必要があるため、非常に困難です。44.1 kHz (音楽録音の標準品質) でサンプリングされた一般的な音楽トラックは、数百万のタイムステップで構成されています。
LlamaやLlama 2のようなテキストベースの生成モデルには、サンプルあたりわずか数千のタイムステップを表すサブワードとして処理されたテキストが供給されます。
この課題へのアプローチとして、EnCodecのニューラルオーディオコーデックを用いて、生の信号から個別のオーディオトークンを学習します。これにより、音楽サンプルに新しい固定の「語彙」が生まれます。そして、これらの離散オーディオトークンに自己回帰言語モデルをトレーニングし、EnCodecのデコーダを使ってトークンをオーディオ空間に変換することで、新しいトークンと新しいサウンドと音楽を生成することができます。
AudioCraftの詳細な情報はこちら。




